
Will Law, chief architect at G&L partner Akamai Technologies, talks about using LL-HLS with range-based addressing for greater interoperability in low-latency streaming.
Introduction
HTTP Adaptive Segmented (HAS) streaming began to be used at scale from 2008 to 2012, with the advent of Move Networks, Microsoft Smooth Streaming, Apple HLS, Adobe HDS, and MPEG DASH. With the typical 10s segment durations of the day, livestream latencies (measuring latency as the time from an action being filmed to that same action being displayed on a device's screen) remained in the 30s to 60s range, trailing broadcast by a significant degree. Over the next decade, segment durations were reduced down to 2s, bringing with them a concomitant reduction in latency to the 8s to 16s range. That range remains the typical latency for many live events today. The year 2020 then brought the industry a pleasant surprise -- not one, but two HAS standards were released that target latency in the 2s range: Low Latency DASH (LL-DASH) and Low Latency HLS (LL-HLS). Both these standards were developed independently, and while they can be deployed as separate streams in a content delivery system, there are performance and cost gains to be had for packagers, origins, CDNs, and players if both streaming formats can be served by a single-set of media objects.
The HLS specification was updated to describe version 10 of the streaming protocol. Among the many improvements, LL-HLS introduces the notion of partial segments ("parts"). Each part can be addressed discreetly via a unique URL, or optionally as a referenced byte-range into a media segment. The vast majority of early implementations have focused on the discreet part-addressing mode. However, range-based addressing brings with it several performance advantages, along with a path to interoperability with LL-DASH solutions and increased CDN efficiency. It also harbors some curious requirements for implementation across general purpose proxy caches.
This article will investigate the problems we can solve with range-based addressing, the requirements it brings to operate effectively, and the benefits we can gain by deploying it at scale.
Cache efficiency
Let's start by examining cache efficiency at the edge when faced with a mixture of low latency and standard latency HLS and DASH clients, all playing the same content. Caching is the means by which CDNs scale up HTTP-adaptive streams. The more content can be cached, the better the performance and the lower the costs. If we imagine an LL-HLS stream with 4s segments and 1s parts, Figure 1 shows all the objects that will need to be cached at the edge within a 4s window. There are many of them! Some are larger than others and we can highlight this difference by scaling them graphically such that the area is proportional to the size. Figure 1 shows that the video segments take up the largest amount of space.
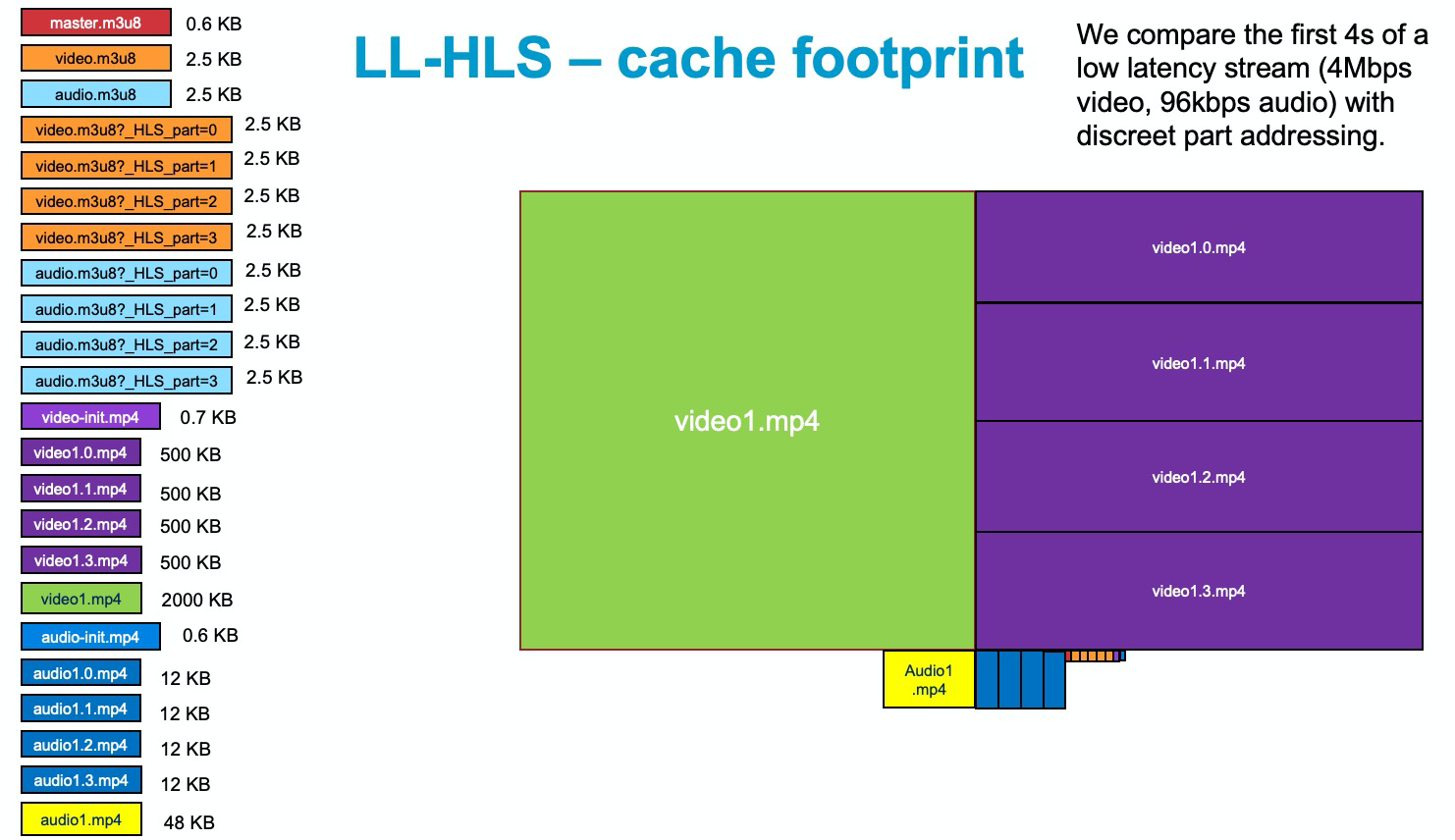 Figure 1
Figure 1
Notice there is duplication in content between the parts (purple), which are consumed by a low latency client playing at the live edge, and the contiguous media segments (green), which are consumed by standard latency clients, or low latency clients scrubbing behind the live edge. If we were to add in the DASH footprint, we would see in Figure 2 that we have three silos of files, all holding the same media content, yet competing with one another for cache space.
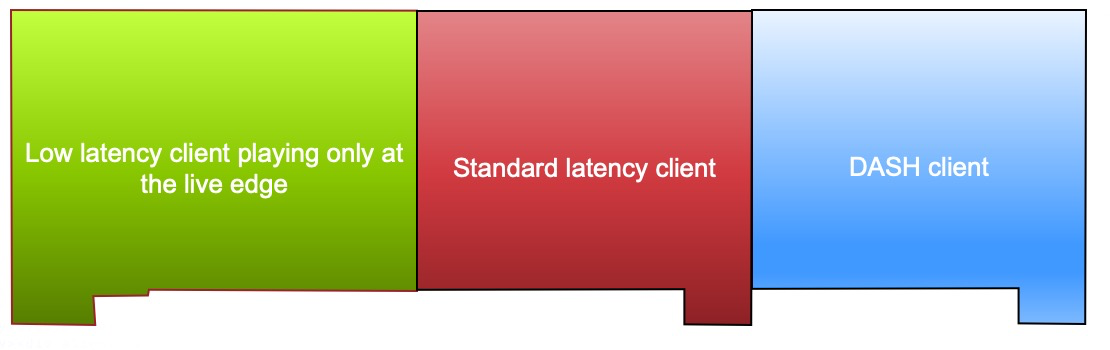 Figure 2
Figure 2
Our goal is to reduce these down to a single silo. This will lower origin storage by a factor of 3 and also triple the cache efficiency for the CDN. This can be achieved through the use of byte-range addressing.
Byte-range addressing
Within an LL-HLS media playlist, a part is described discreetly using a unique URL for every part. For example:
#EXT-X-PART:DURATION=0.500,URI="segment1000-6.m4s"
This same part can alternatively be described using the BYTERANGE syntax:
#EXT-X-PART:DURATION=0.500,URI="segment1000.m4s",BYTERANGE=251022@2079557
which specifies the length and offset at which a part is located within a media segment. For PRELOAD HINT parts, for which the last-byte-position is not yet known, only the start of the byte range is signalled:
#EXT-X-PRELOAD-HINT:TYPE=PART,URI="segment1000.m4s",BYTERANGE-START=2005479
Figure 3 shows a discreet part playlist on the left, and it's byte-range-addressed equivalent on the right:
 Figure 3
Figure 3
Of particular interest to us is the expected origin behavior when faced with the open range request specified by the PRELOAD HINT entry. According to the HLS spec, "When processing requests for a URL or a byte range of a URL that includes one or more Partial Segments that are not yet completely available to be sent - such as requests made in response to an EXT-X- PRELOAD-HINT tag - the server MUST refrain from transmitting any bytes belonging to a Partial Segment until all bytes of that Partial Segment can be transmitted at the full speed of the link to the client." This means that the origin must hold back beginning the response until all the bytes of that preload part are available. But what then? The spec continues: "If the requested range includes more than one Partial Segment then the server MUST enforce this delivery guarantee for each Partial Segment in turn. This enables the client to perform accurate Adaptive Bit Rate (ABR) measurements." Since our open range request does include more than one part (in fact, it includes all the remaining parts of that segment), the origin should continue to return successive parts down the same response, bursting each part as it becomes fully available. The key point here is that that single request will in fact return all the parts remaining in that segment. Figure 4 illustrates how we can use this fact to derive a common workflow between LL-HLS and LL-DASH.
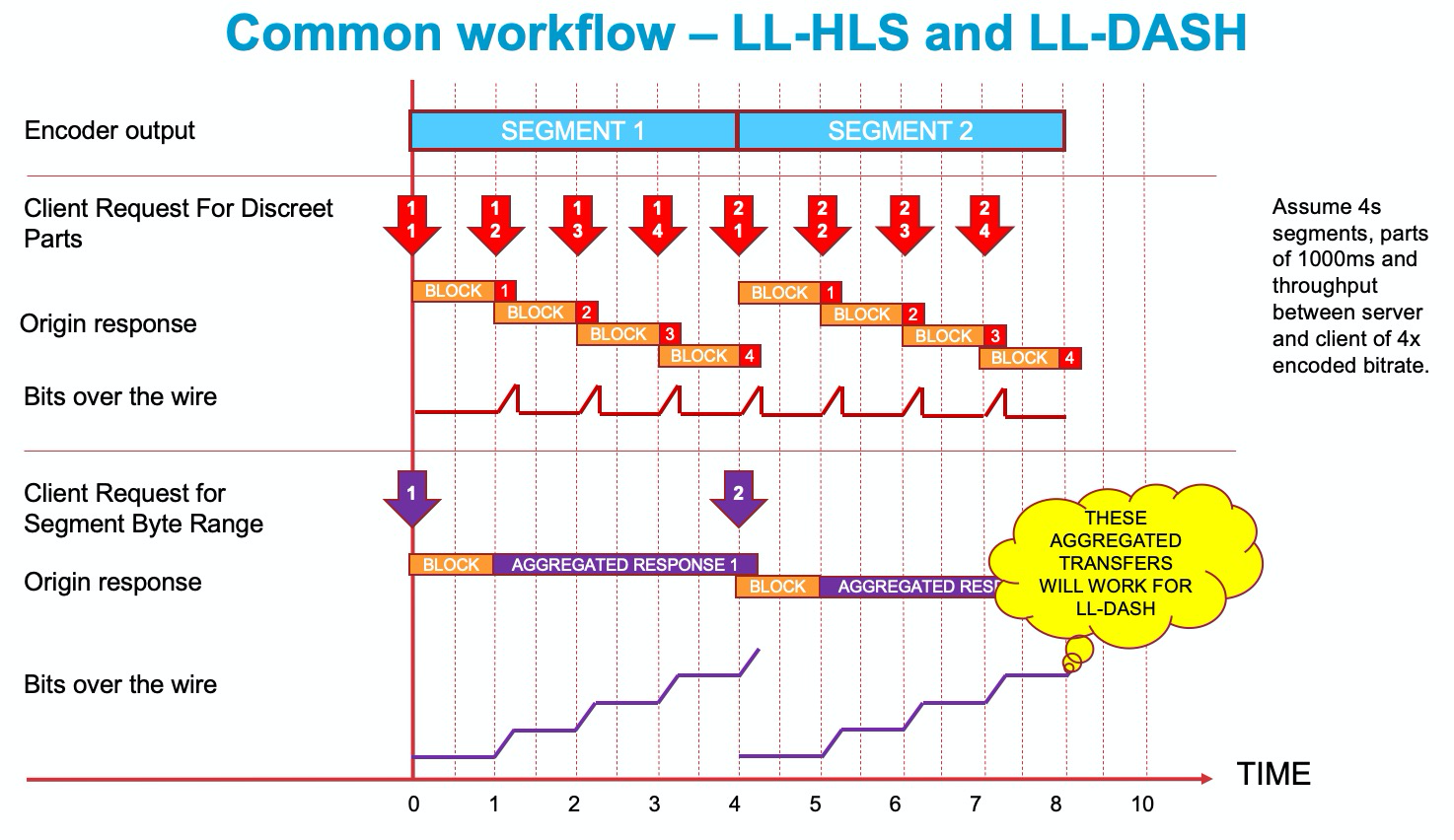 Figure 4
Figure 4
The lower half of Figure 4 represents the workflow for a client using byte range addressing. At time 0, it makes an open-ended range request against segment 1. The origin blocks the response until the entirety of part 1 is available and then it begins an aggregated response back to the client. I use the term "aggregated" carefully here. If this were http/1.1, it would be a chunked transfer response, however since LL-HLS mandates the use of http/2, and http/2 has framing, this is simply an aggregating http/2 response. Notice that bytes are injected into the byte-addressed response at the exact same time as they are released down the wire for the discreet-addressed parts. The two approaches are latency-equivalent. Also, importantly -- the aggregating response in the byte-addressed case is exactly what an LL-DASH client is expecting. DASH clients do not have the constraint that the part (or "chunk" in their context) must be burst, but this bursting does not hurt them and in fact it helps considerably with their bandwidth estimation.
Request-rate benefits
Let's examine the start-up behavior of a byte-range-addressed LL-HLS client. Consider a client faced with the media playlist at start-up (post tune-in) in Figure 5.
 Figure 5
Figure 5
It could simply act as a discreet-addressed client would, which is to make seven independent requests for each individual part. The last request would be an open one for the PRELOAD part. Another option, however, is that it could simply make a single request, as shown in Figure 6.
 Figure 6
Figure 6
This single request would return all the parts, in the correct sequence, all at line speed and including all the future parts that will follow the PRELOAD part. This is exactly what the player needs and (for this ratio of part duration to segment duration) it can be accomplished with a seven-fold decrease in media object requests. Since one of the negatives of LL-HLS is its high request rate against an edge, this is a promising benefit. However, there's a problem in deploying this and it relates to exactly how a CDN edge will interpret that open-range request.
The problem with open-ended range requests
Imagine you are an edge server, and you receive a client request for range=0 against an object whose size you do not yet know. Let's imagine its actual size is 1000B and you have the first 100B received at the edge. Do you:
- Wait until you have received an EOF signal and return a 200 response code with content-length 1000?
or - Immediately return the 100B you do have in an open-ended 206 response and close the response once the 1000th byte is delivered?
Behavior 1 is actually how most CDNs would behave today, yet 2 is the behavior that we need for our low latency streaming to work. Since both are valid use-cases, how can an edge server tell what behavior to enact? Luckily, there is an RFC to the rescue! RFC8673 says that the client should never make an open-ended range request if it is expecting an aggregated response from a fixed offset. It should instead send a request with a very large number as the last-byte-pos in the range request. 9007199254740991 has been proposed as a candidate (this equals Number.MAX_SAFE_INTEGER for 64 bit systems). This would signal the proxy-server (or origin) to begin a 206 response that starts at the requested offset and aggregates over time until the object is completely transferred. Note that this convention is only required when the start-byte-pos of the range request is non-zero. If the range being requested starts at zero, then a standard (non-range) GET request can be used, as the origin will naturally provide the aggregating response.
With this RFC in mind, let's examine the start-up behavior again. There are three scenarios we should consider. The first is for a player tuning-in to the playlist shown below in Figure 7:
 Figure 7
Figure 7
In order to commence playback, it would walk back from the live edge and find the latest independent part (highlighted in yellow). It would then make the following request:
GET / v1_1-7728.m4s HTTP/2
Notice that the RFC8673 convention is not needed here since the starting offset is zero. The server would respond with:
HTTP/2 200
The origin would respond by bursting the bytes it has (up to 375122) and then releasing the remainder as each part boundary becomes available. This would give the player the independent part it needs to start, plus all the segments up to and including the HINTed part. The response would not include a content-length header, as the size is not known. If this were an HTTP1.1 connection, it would be signalled as a Chunked Transfer Encoding response, but since LL-HLS mandates H2 connections to the client, this is simply seen by the client as an aggregating response.
The second start-up case concerns an independent part at a non-zero offset into the segment. The media playlist might look like Figure 8:
 Figure 8
Figure 8
This media segment has two independent parts and we wish to start with the latest one to minimize our latency. The client would first ask for:
GET / v1_1-7728.m4s HTTP/2
Range: bytes=245668-9007199254740991
Note that the request has a first-byte position of 245668 instead of zero, which requires the use of the RFC8673 convention. The server would respond with:
HTTP/2 206 Partial Content
Content-Range: bytes 245668-9007199254740991/*
The origin responds by acknowledging the convention established by RFC8673 in the content-range header, along with signalling the content length as * since it is not yet known. It would then burst the bytes from 245668 to 375123 and release the remainder as each part boundary became available.
The third and last start-up case is the edge condition in which the PRELOAD hint represents the start of a new segment.
 Figure 9
Figure 9
Notice in Figure 9 that the HINT belongs to segment 7729 (purple highlight) while the prior segment 7728 holds the independent part we need to start with. To start up, the player needs to make two requests. The first would be:
GET / v1_1-7728.m4s HTTP/2
Range: bytes=245668-498933
Since segment 7728 is completely available, the player knows the content-length of the segment so it does not need to use the RFC8673 very-big-number convention. It simply asks for the byte range from the start of the last independent part to the end of the segment. The server would respond with:
HTTP/2 206 Partial Content
Content-Length: 253265
Content-Range: bytes 245668-498933/498934
This is a conventional 206 response. Since the content-length is known, the Content-Length response header is added. All the data would be burst as one contiguous block as the segment is fully available at the origin. The client would then need to make a second request to continue playback:
GET / v1_1-7729.m4s HTTP/2
The server would respond with:
HTTP/2 200
The server bursts all the parts of segment 7729 as they become available in an aggregating response and the player is off to steady-state playback.
Steady State
Speaking of steady state, what does that look like? If we were to examine all the requests crossing the wire after the player has started, they would look like this:
GET / v1_1-7729.m4s HTTP/2
Range: bytes=567843-9007199254740991
GET / v1_1-7730.m4s HTTP/2
GET / v1_1-7731.m4s HTTP/2
GET / v1_1-7732.m4s HTTP/2
...
Aside from the very first request, which uses the RFC8673 convention due to the non-zero starting offset, these are all standard GET requests without range headers. Surprisingly, we can make the general observation that an LL-HLS client using byte range addressing need only make one request per segment duration for each media type. This is nice performance gain for LL-HLS, which otherwise is quite a verbose format. Note that the client must still refresh its media playlists at the respective part duration interval, as those provide it with information on the changing state of the stream. The reduction in overall request rate is dependent on the ratio of part duration to segment duration. Table 1 shows the number of requests made per segment duration of wall clock interval for an LL-HLS client using either discrete or range-based part addressing.
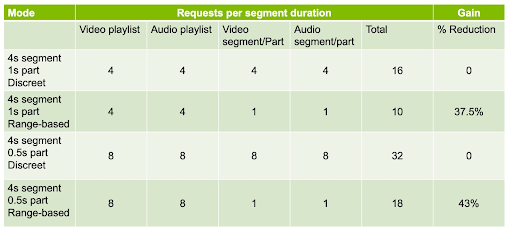
Table 1
For the case of 4s segments and 1s parts, we see a 37.5% reduction in the overall number of requests every 4s. If the parts are reduced to 0.5s in duration, then that reduction rises to 43%. That is a material gain that is important for CDN scalability and overall system cost. For a million connected clients, having 430,000 fewer requests every 4s is a material difference. Each request against a CDN has a cost -- in connections, compute, and power. For maximum distribution efficiency, we want to minimize our requests while maximizing the end user's quality of experience.
Segment structure
Early versions of the LL-HLS origins produced parts that were all independent (i.e., each one contained a keyframe) and then had contiguous segments with a single keyframe, as represented in Figure 10.
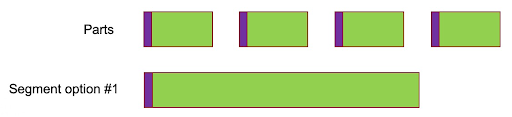
Figure 10
The reason for this is encoding efficiency -- there is a small gain in encoding efficiency by moving to the longer GOP. However this arrangement breaks the portability of having a single object be stored in cache from which we can serve both parts and segments. In order to achieve a unified cache, our segment must be a direct concatenation of our parts, as represented in Figure 11.

Figure 11
The benefits to be gained by halving the cache footprint far outweigh the small encoding efficiency gains to be had by having two bit-different objects.
Estimating throughput
All HTTP adaptive streaming clients must use the download of the media segments in order to estimate the available throughput and thereby allow their ABR algorithm to switch-up.
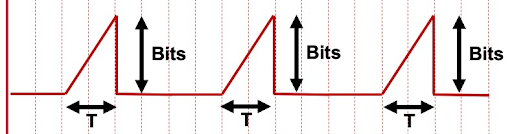
Figure 12
With discreet part delivery, this is done by measuring the bits received and dividing by the time taken to receive them, as illustrated in Figure 12. Since the objects are fully available at the server, the rate at which they are delivered is limited by the line speed and hence can be used to estimate how much throughput overhead is available. If the same logic is followed for an aggregating range-addressing response, it will provide an incorrect response. The bit numerator will be correct, but the denominator will include the time the origin was blocking delivery, as in Figure 13.
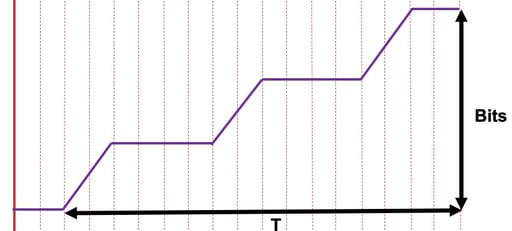
Figure 13
The player will keep dividing the total bits of the media segment by the delivery time, which is essentially the media playback time of the segment. This result will always return that the estimated throughput is equal to the encoded bitrate of the object -- a useless result that will be both inaccurate and prevent the player from ever switching up to a higher bitrate tier.
What the player must do instead is only estimate throughout when the bits-across-the-wire are increasing, as shown in Figure 14.
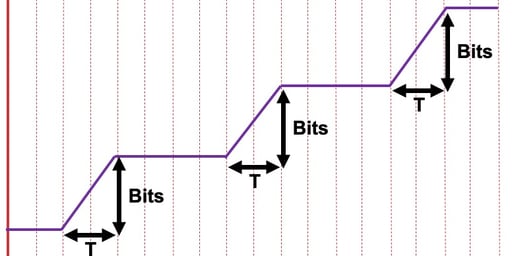
Figure 14
How can the player do this? Well, conveniently, the media playlist described the part boundaries as ranges and the origin and edge server are required to always burst parts. So if the player monitors its receive buffer it can mark the wall-clock time at which the part boundaries are received and hence calculate the throughput over the correct portion of the aggregation window.
Enough theory -- Does this work in the real world?
To validate the concepts described in this blog across the real internet, I collaborated with Ateme, a France-based provider of encoder and origin servers. Ateme mounted an encoder and LL-HLS origin in a AWS instance in the state of Virginia in the United States. I then placed the Akamai CDN on top of this and used it to stream to a client located in San Francisco, California, as shown in Figure 15.

Figure 15
The player was a test harness that I wrote in Javascript, so that it could be run in a web browser. A browser-based player is a very convenient endpoint from which to validate requests, timing, and CDN performance. Figure 16 is a screenshot of the livestream in action.
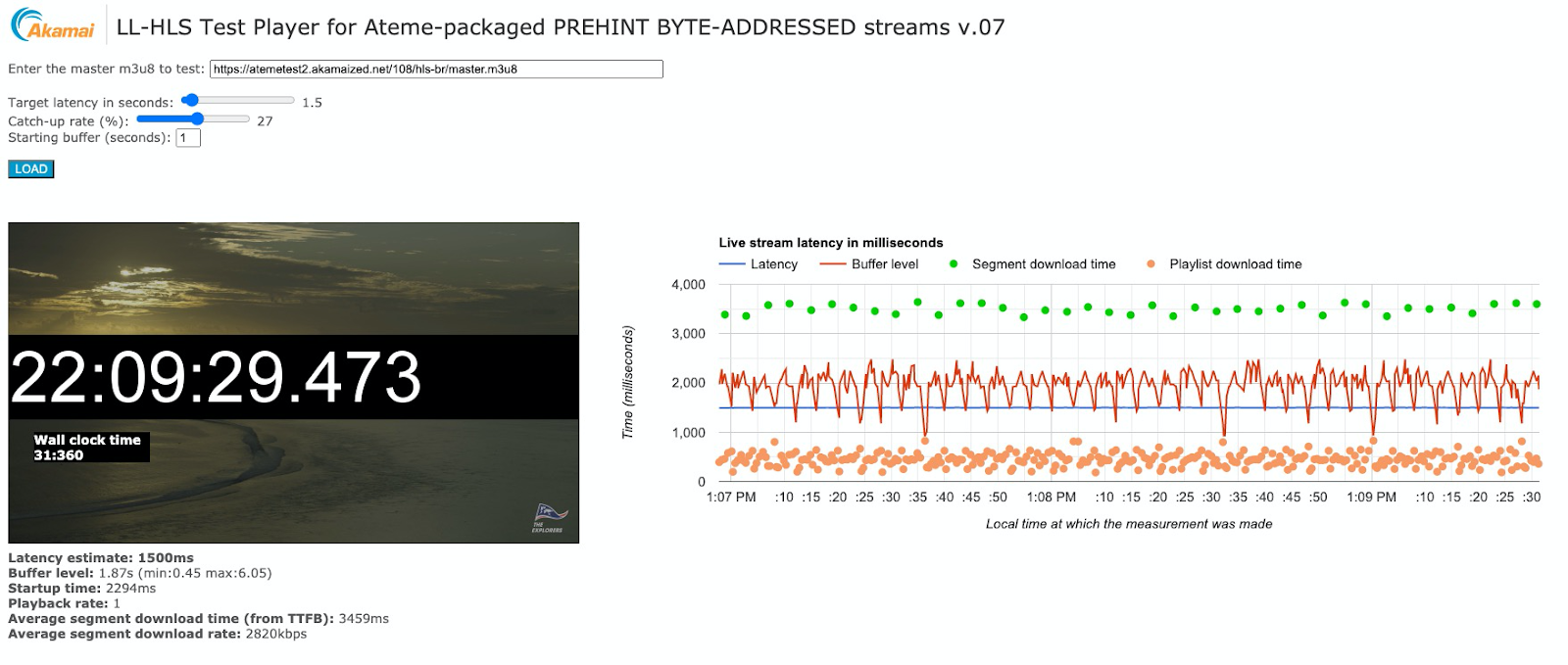
Figure 16
This stream contains 4s segments with 0.5s parts. It is operating at its target end-to-end latency of 1.5ss. In the chart on the right the green dots show the completion of each media segment request. These all take just under 4s, which is what we would expect. The orange dots represent the media playlist updates, which are occurring every 500ms. By examining the video object requests in Figure 17,
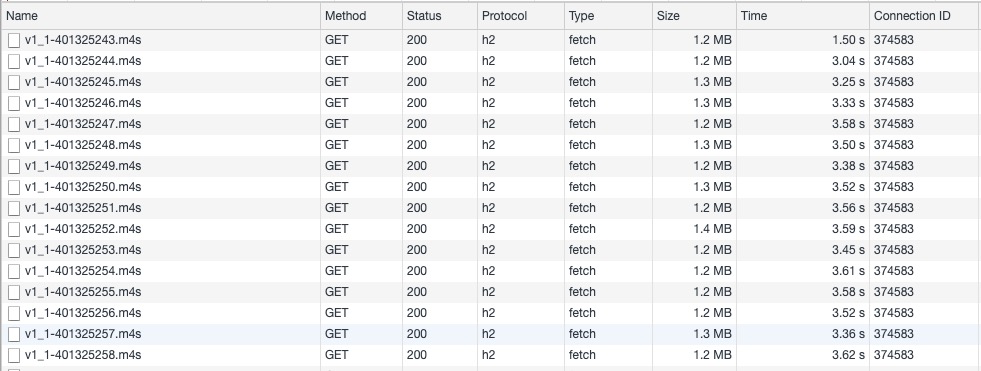
Figure 17
we can see that the requests are only made against the segments and that each receives a 200 response from the edge server and takes just under 4s to complete. It is a curious fact that even though we are using range-based addressing with LL-HLS, under steady playback the client does not need to make any range-based requests! If an initial request had been made at a non-zero offset, it would have used the RFC8673 convention and this would show as a 206 response preceded by a CORS preflight OPTIONS request to verify that the range header is allowed. This preflight request is an artifact of testing from a web browser and would not be present if testing from a native app. The media playlist updates in comparison (in Figure 18) are returned much faster than the media segments, at roughly 500ms intervals. Notice each one asks for a successively newer version of the playlist using the reserved _HLS_msn and -HLS_part query args.
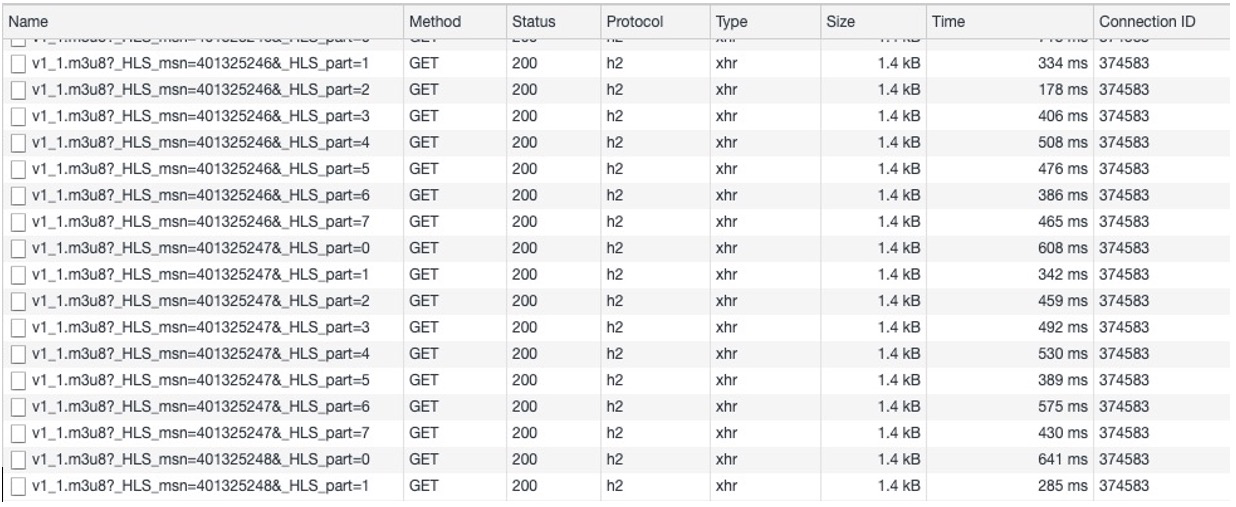
Figure 18
Figure 19 shows a detail of one of the media segment requests. Note that there is no content-range response header since the client is asking for the full segment and there is no content-length response header since this is an aggregating H2 response against an object of unknown size.
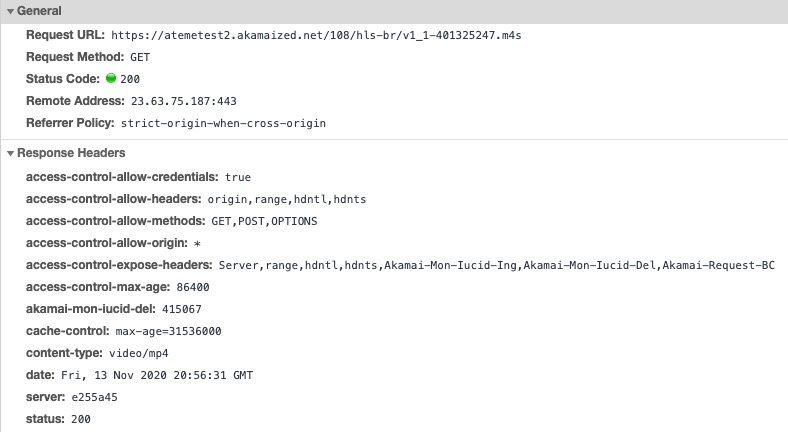
Figure 19
Figure 20 shows our three target players all playing together from the same origin and edge server. On the lower left is the LL-HLS player in byte-range addressing mode. Upper left is the LL-DASH player. On the right is a standard latency HLS player, represented by HLS.js.
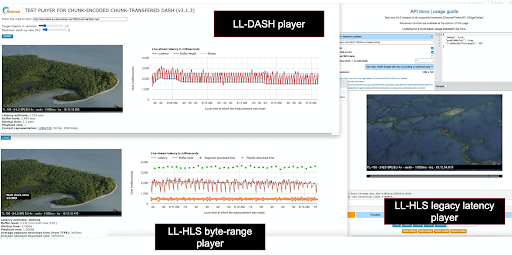
Figure 20
This standard latency player is playing the exact same stream as the LL-HLS player, but is 12s behind, since it ignores the parts and instead builds three of the 4s segments in its source buffer before starting. Figure 21 is basically validation of the whole approach espoused by this document. It shows the network panels of the three players arranged adjacent to one another. You'll notice that each player is pulling the same media segment from the edge; 1-401326000.m4s,- for example.
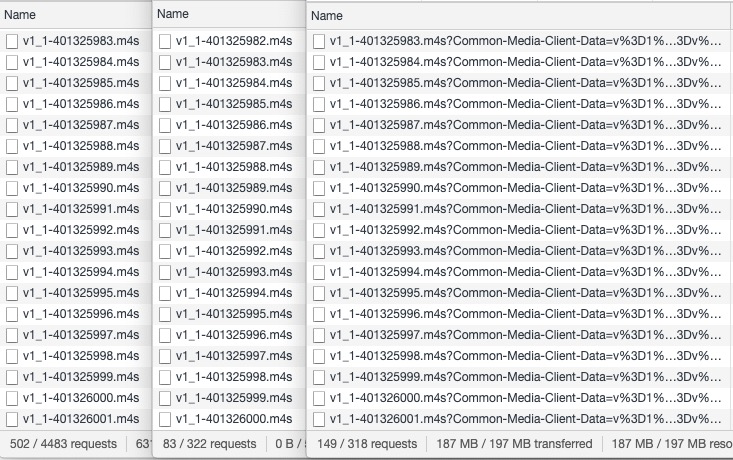
Figure 21
The panel in the center belongs to the legacy latency player and it is always a full segment behind the other two players, which are both low latency and pull the object while it is still being produced. If we examine the first player to request a given segment from the CDN edge, we notice that it receives a TCP_MISS response (Figure 22). This indicates that the content was not available at the edge and that the edge had to make a forward request to the origin to retrieve it. This is normal behavior as at least one request must always go to the origin to retrieve the content.

Figure 22
What is important is that the second and subsequent requests for the same object received a TCP_HIT response (Figure 23). This indicates that the object is in fact being cached at, and served from, the edge. Success!
Conclusion
The advent of range-based addressing for LL-HLS opens up a number of benefits for distributors of livestreams:
- Increased cache efficiency at origin and CDN distribution tiers, which increases performance and lowers operating costs
- Decreased request rate from clients. We showed reductions of 30% to 40% for typical encoding configurations, which allows increased CDN-supported scale, lowers operating costs, and reduces the incidence between request errors.
- An LL-HLS client under steady-state playback does not need to make any range-requests against the origin even when range-based addressing is used in the playlist.This removes the CORS preflight requirements for browser-based clients, improving the latency with which playlists and segments can be returned.
- Interoperability among four types of clients: low latency HLS clients, standard latency HLS clients (also equivalent to LL-HLS clients scrubbing back from live), low latency DASH clients, and standard latency DASH clients
- If a CDN is present in the distribution chain, then it requires support for RFC8673 at the origin, CDN, and client layers to work effectively. If the clients are talking directly to the origin, then the origin can be expected to behave appropriately and no RFC8673 convention would be required.
We are pleased to announce the Akamai is now supporting RFC8673 in production as of October 30, 2020, via our Adaptive Media Delivery (AMD) product. It needs to be activated through metadata so please contact your account representative if you are interested in testing.
We look forward to the advent of interoperable low latency streaming at scale. If you have any questions, please don't hesitate to get in touch with me directly.