
Will Law, Chief Architect bei G&L-Partner Akamai Technologies, über die Verwendung von LL-HLS mit bereichsbasierter Adressierung für mehr Interoperabilität im Low-Latency-Streaming.
Einleitung
Zwischen 2008 und 2012 begann das HAS-Streaming (HTTP Adaptive Segmented) mit Move Networks, Microsoft Smooth Streaming, Apple HLS, Adobe HDS und MPEG DASH eine breitere Verwendung zu finden. Mit einer typischen Segmentdauer von 10 Sekunden lagen die Latenzen beim Live-Streaming – also die Zeit zwischen Aufnahme und tatsächlicher Wiedergabe am Bildschirm –weiterhin im deutlich verzögerten Bereich von 30 bis 60s. Im Laufe des nächsten Jahrzehnts wurde die Segmentdauer auf 2s und die Latenzen damit auf 8 bis 16s verringert. Bei vielen Live-Übertragungen ist das bis heute die Norm. Im Jahr 2020 wurde die Branche angenehm überrascht, indem die 2-Sekunden-Latenz gleich von zwei neuen HAS-Standards angegangen wurde: Low Latency DASH (LL-DASH) und Low Latency HLS (LL-HLS). Beide unabhängig voneinander entwickelten Standards können von Inhaltsanbietern als separate Streams in einem Content Delivery System eingesetzt werden. Gleichwohl ergeben sich Leistungs- und Kostenvorteile für Paketanbieter und Origins, CDNs und Player, sofern beide Formate von den gleichen Medienobjekten bedient werden.
Die HLS-Spezifikation wurde zur Anpassung an Version 10 des Streaming-Protokolls aktualisiert. Neben vielen weiteren Verbesserungen werden mit LL-HLS auch so genannte Teilsegmente („Parts“) eingeführt. Jedes Teil lässt sich über eine eigene URL ansprechen oder optional auch als Byte-Range in ein Mediensegment einbinden. Erste Anwendungen haben sich überwiegend für die separate Teiladressierung entschieden. Eine Byte-Range-Adressierung bringt neben einigen Leistungsvorteilen jedoch auch eine größere Kompatibilität mit LL-DASH-Lösungen sowie eine größere Effizienz von CDN mit sich. Zudem beinhaltet sie einige interessante Anforderungen für Implementierungen über universelle Proxy-Cache-Server.
Dieser Artikel untersucht die mit der Byte-Range-Adressierung lösbaren Probleme, die für einen effektiven Betrieb erforderlichen Voraussetzungen und die Vorteile, die wir durch einen großflächigen Einsatz erzielen können.
Cache-Effizienz
Zunächst soll die Cache-Effizienz untersucht werden, wenn mehrere verschiedene HLS- und DASH-Clients die gleichen Inhalte mit niedriger und normaler Latenz abspielen. HTTP-adaptive Streams skalieren mittels des CDN Caches. Je mehr Content gecached wird, desto mehr steigt die Performance und desto geringer sind die Kosten. Die in Abbildung 1 dargestellten Objekte müssen innerhalb eines 4s breiten Fensters gecacht werden, wenn der zu streamende LL-HLS-Inhalt aus 4 s langen Segmenten und 1s langen Parts besteht. Und von diesen Objekten gibt es viele! Der Größenunterschied zwischen den einzelnen Objekten wird deutlicher, wenn sie grafisch so skaliert werden, dass der Bereich dem Größenverhältnis entspricht. Abbildung 1 macht deutlich, dass die Videosegmente den meisten Platz benötigen.
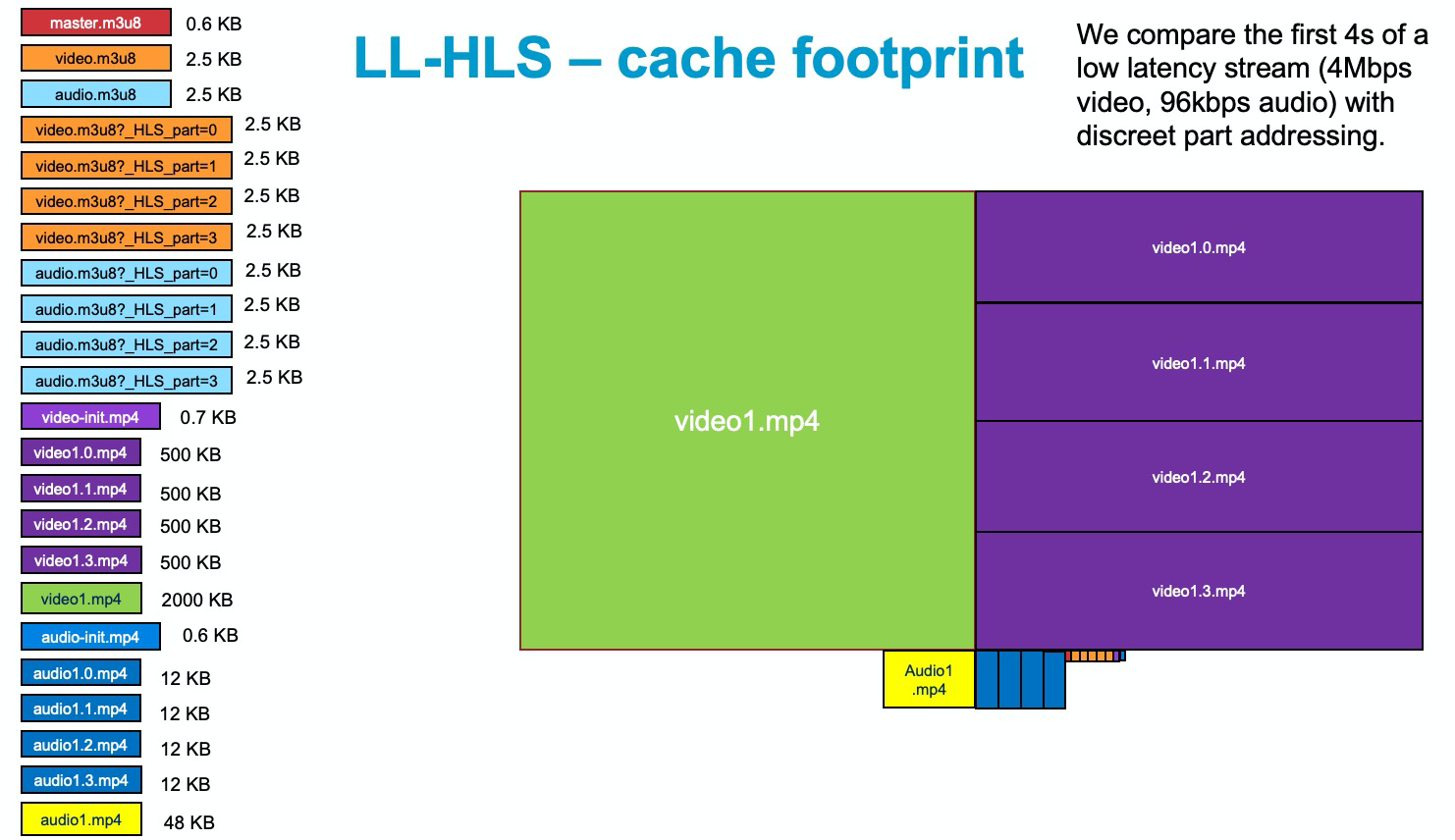 Abbildung 1
Abbildung 1
Hier fällt auf, dass die von einem Low-Latency Client aufgenommenen Parts am Rand der Liveübertragung (violett) und die angrenzenden Mediensegmente (grün) in Clients mit normaler Latenz bzw. Clients mit niedriger Latenz außerhalb des Live-Bereichs den gleichen Inhalt aufweisen, der sich dadurch verdoppelt. Nach Ergänzung des DASH-Bereichs ergeben sich die in Abbildung 2 dargestellten drei separaten Dateistapel mit jeweils dem gleichen Mediencontent, aber konkurrierendem Bedarf an Cachespeicherplatz.
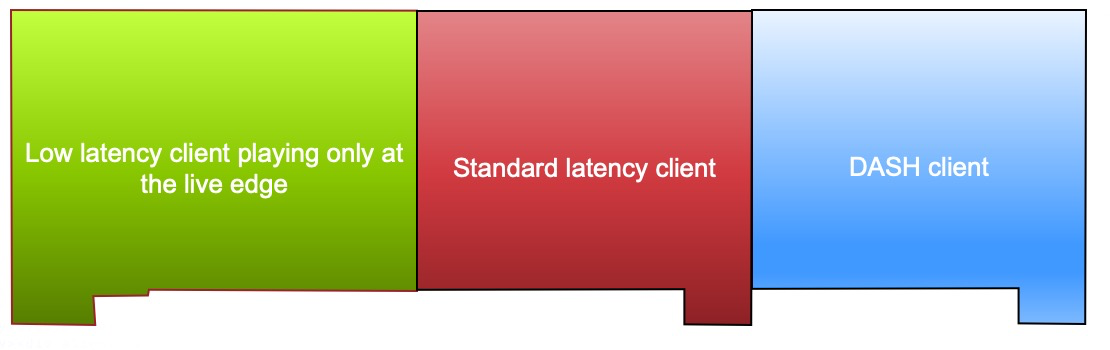 Abbildung2
Abbildung2
Diese drei Stapel sollen auf einen Stapel reduziert werden, was den Speicherbedarf für den Originalcontent auf ein Drittel verringern und daher die Cache-Effizienz des CDN verdreifachen würde. Das lässt sich mit Hilfe der Byte-Range-Adressierung erreichen.
Byte-Range-Adressierung
Parts in einer LL-HLS-Media-Playlist werden jeweils durch ein eindeutige URL beschrieben. Beispiel:
#EXT-X-PART:DURATION=0.500,URI="segment1000-6.m4s"
Das gleiche Teil lässt sich alternativ auch mit der BYTERANGE-Syntax beschreiben:
#EXT-X-PART:DURATION=0.500,URI="segment1000.m4s",BYTERANGE=251022@2079557
Hierbei sind Länge und Offset des Teils und damit seine genaue Position innerhalb des Mediensegments angegeben. Bei PRELOAD HINT-Parts ist die letzte Byteposition noch nicht bekannt, weshalb hier lediglich der Beginn des Bytebereichs genannt wird:
#EXT-X-PRELOAD-HINT:TYPE=PART,URI="segment1000.m4s",BYTERANGE-START=2005479
Abbildung 3 stellt eine Playlist mit diskreten Parts (links) der entsprechenden Byte-Range-Adressierung (rechts) gegenüber:
 Abbildung 3
Abbildung 3
Von besonderem Interesse ist an dieser Stelle die erwartete Reaktion des Origin auf die hinter „PRELOAD HINT“ definierte offene Range. In der HLS-Spezifikation heißt es: „Wird eine URL oder einer ihrer Bytebereiche angefordert, in dem ein oder mehrere noch nicht vollständig für den Versand verfügbare Teilsegmente liegen – also zum Beispiel Requests mit dem Tag EXT-X-PRELOAD-HINT – darf der Server ein Teilsegment erst übertragen, wenn alle Bytes des jeweiligen Teilsegments mit voller Datenrate der Clientverbindung übertragen werden können.“ Der Origin darf die Response also erst einleiten, wenn alle Bytes des Preload-Parts verfügbar sind. Und dann? In der Spezifikation heißt es weiter: „Enthält der angeforderte Bereich mehr als ein Part, muss der Server seinerseits die garantierte Übertragung jedes Teilsegments erzwingen. Dadurch kann der Client präzise Messungen der Adaptiven Bitrate (ABR) vornehmen.“ Da die angeforderte Range mehr als ein Part (tatsächlich sogar alle verbleibenden Parts dieses Segments) enthält, muss der Origin die Parts nacheinander als Teil der gleichen Response senden, und zwar unmittelbar, sobald ein Part vollständig verfügbar ist. Entscheidend ist, dass ein einzelner Request alle Parts eines Segments als Response erhält. Abbildung 4 verdeutlicht, wie sich diese Tatsache für einen gemeinsam Ablauf von LL-HLS und LL-DASH nutzen lässt.
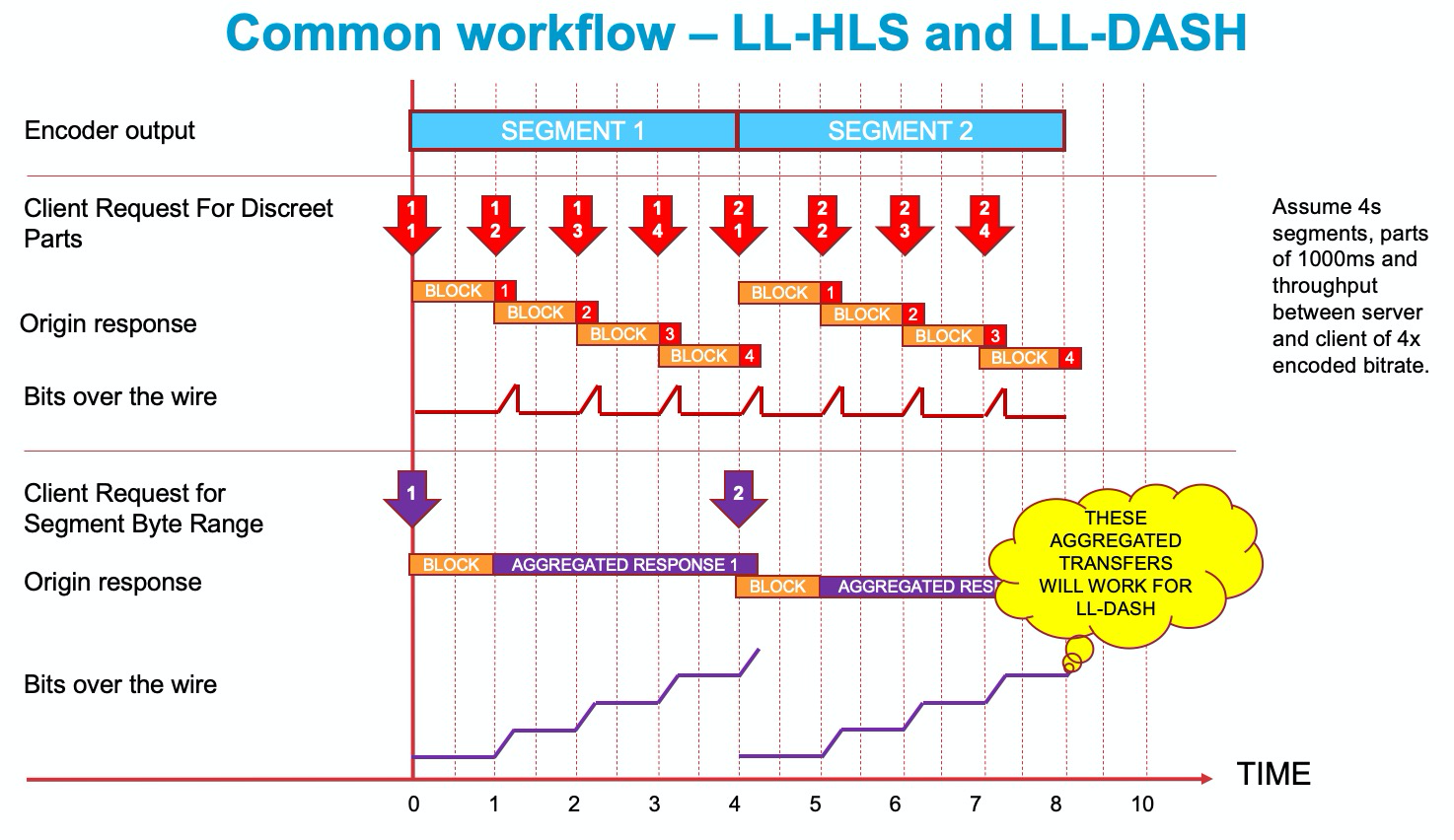 Abbildung 4
Abbildung 4
Der untere Bereich von Abbildung 4 stellt den Ablauf eines Clients mit Byte-Range-Adressierung dar. Zum Zeitpunkt 0 wird ein offener Bereich von Segment 1 angefordert. Die Quelle verzögert die Response, bis der gesamte Teil 1 verfügbar ist. Anschließend erfolgt die Sammel-Response an den Client. Der Begriff „Sammel-Response“ ist hier mit Bedacht zu verwenden. Ginge es hier nämlich um http/1.1, bestünde die Response aus einem Chunk-Transfer. Da für LL-HLS jedoch unbedingt http/2 einzusetzen ist und da http/2 mit Frames arbeitet, handelt es sich hier einfach um eine Sammel-Response gemäß http/2. Hierbei ist zu beachten, dass die Ablage der Bytes in der byteadressierten Response genau im Moment der vorgelagerten Absendung für die einzeln adressierten Parts erfolgt. Beide Verfahren sind latenzäquivalent. Wichtig ist weiterhin, dass die Sammel-Response im Falle der Byteadressierung dem vom LL-DASH-Client erwarteten Paket entspricht. Für DASH-Clients ist eine Byte-Bündelung des Teils (bzw. des „Chunks“) nicht erforderlich, schadet aber auch nicht, sondern hilft sogar erheblich bei der Bandbreitenabschätzung.
Request-Rate Vorteile
Als nächstes soll das Startverhalten eines Byte-Range-adressierten LL-HLS-Clients betrachtet werden. Der Client soll beim Start (nach dem Einschalten) die Media Playlist aus Abbildung 5 erhalten.
 Abbildung 5
Abbildung 5
Er könnte darauf wie jeder Client bei einer diskreten Adressierung reagieren, indem er zu jedem Teil sieben unabhängige Requests generiert, deren letzte eine offene Anforderung des PRELOAD-Teils wäre. Alternativ könnte er auch nur eine Einzelanforderung wie in Abbildung 6 generieren.
 Abbildung 6
Abbildung 6
Auf diese Einzel-Requests würden alle Parts in der richtigen Reihenfolge bei voller Leitungsgeschwindigkeit gesendet, und zwar einschließlich aller späteren Parts nach dem PRELOAD-Teil. Genau das benötigen die Player (bei diesem Verhältnis von Part- und Segmentdauer) und es lässt sich zudem mit nur noch einem Siebtel der Medienobjekt-Requests erreichen. Da einer der Nachteile von LL-HLS in der hohen Anzahl an Requests besteht, klingt das nach einer deutlichen Verbesserung. Dabei besteht jedoch ein Problem mit der Interpretation der Anforderung eines offenen Bereichs durch den Edge-Server des CDNs.
Problem mit open-ended Range Requests
Stellen wir uns einen Edge-Server vor, der von einem Client eine Anforderung mit Bereich=0 eine Objekts erhält, dessen Größe noch nicht bekannt ist. Nehmen wir die tatsächliche Größe mit 1000 Byte an, von denen die ersten 100 Bytes bereits im Edge-Server liegen. Mögliche Response:
- Bis zum Eintreffen einen EOF-Signals warten und mit dem Response-Code 200 und der Inhaltslänge 1000 antworten
oder - Die vorhandenen 100 Bytes in einer offenen Response mit Code 206 sofort zurücksenden und die Anforderung nach Versendung des 1000. Bytes abschließen.
Die meisten heutigen CDNs würden den ersten Weg gehen, obwohl der zweite für ein Streamen mit geringer Latenz optimal wäre. Wie soll ein Edge-Server sein Verhalten bestimmen, wenn doch beide Alternativen gültige Anwendungsfälle darstellen? Glücklicherweise besteht hierzu ein RFC-Dokument! In RFC8673 ist festgelegt, dass der Client keine offenen Bereiche anfordern soll, wenn von einem festen Offset eine Sammel-Response zu erwarten ist. Stattdessen sollte die letzte Byteposition der offenen Anforderung mit einer sehr großen Zahl angegeben werden. Dazu wurde die Zahl 9007199254740991 als möglicher Kandidat vorgeschlagen (das entspricht Number.MAX_SAFE_INTEGER in 64-Bitsystemen). Dadurch würde der Proxyserver (bzw. der Origin) angewiesen, beim angeforderten Offset eine Response mit Code 206 zu beginnen und diese allmählich kumulieren, bis das Objekt komplett übertragen wurde. Diese Festlegung gilt jedoch nur, wenn die Bereichsposition des Startbytes der Anforderung ungleich null ist. Beginnt der angeforderte Bereich dagegen bei null, kann auch die Standardanforderung GET (ohne Bereich) verwendet werden, da der Origin hierauf mit der Sammel-Response reagiert.
Vor diesem Hintergrund kann das Anfangsverhalten neu beurteilt werden. Drei Szenarien sind zu betrachten. Das erste gilt für das Abspielen der Playlist aus Abbildung 7:
 Abbildung 7
Abbildung 7
Um mit der Wiedergabe zu beginnen, sucht der Vorgang beginnend am Livestream-Ende nach dem (in Gelb markierten) neuesten unabhängigen Part und sendet anschließend die folgende Anforderung:
GET / v1_1-7728.m4s HTTP/2
Da das Anfangs-Offset in diesem Fall null beträgt, ist die Festlegung nach RFC8673 nicht erforderlich. Response des Servers:
HTTP/2 200
Der Origin bündelt die vorliegenden Bytes (bis zu 375122) und schiebt den Rest bei Erreichen der einzelnen Parts-Grenzen nach. Dadurch erhält der Player das für den Beginn der Wiedergabe erforderlich Part sowie alle Segmente bis einschließlich dem HINT-Teil. Da die Inhaltslänge nicht bekannt ist, enthält die Response auch keinen entsprechenden Header. Im Falle einer HTTP1.1-Verbindung würde die Response als Chunked Transfer Encoding erfolgen. Da LL-HLS jedoch H2-Verbindungen mit dem Client verlangt, erkennt der Client einfach eine Sammel-Response.
Im zweiten Start-Szenario liegt ein unabhängiges Teil mit einem Offset ungleich null im Segment vor. Es ergibt sich eine Playlist ähnlich der in Abbildung 8:
 Abbildung 8
Abbildung 8
Dieses Mediensegment enthält zwei unabhängige Parts. Zur Verringerung der Latenz soll mit dem späteren begonnen werden. Zunächst sendet der Client folgende Anforderung:
GET / v1_1-7728.m4s HTTP/2
Range: bytes=245668-9007199254740991
In der Anforderung liegt das erste Byte an Position 245668 statt bei null, was eine Festlegung nach RFC8673 erfordert. Response des Servers:
HTTP/2 206 Partial Content
Content-Range: bytes 245668-9007199254740991/*
Der Origin bestätigt zunächst die Festlegung nach RFC8673 im Content-Range Header und gibt die Inhaltslänge mit * zurück, da die Länge ja noch nicht bekannt ist. Anschließend bündelt sie die Bytes von 245668 bis 375123 und schiebt den Rest bei Erreichen der einzelnen Teilgrenzen nach.
Das dritte und letzte Start-Szenario besteht aus der Edge-Bedingung, bei der der PRELOAD-HINT den Beginn eines neuen Segments darstellt.
 Abbildung 9
Abbildung 9
Gemäß Abbildung 9 gehört der HINT zu Segment 7729 (violett), während das vorhergehende Segment 7728 das unabhängige Teil für den Start der Wiedergabe enthält. Der Start erfolgt mit zwei Requests des Players. Erstens:
GET / v1_1-7728.m4s HTTP/2
Range: bytes=245668-498933
Da Segment 7728 vollständig vorliegt, kennt der Player die Content-Length des Segments und benötigt keine sehr große Bytezahl gemäß RFC8673. Stattdessen fordert er einfach den Bytebereich vom Beginn des letzten unabhängigen Teils bis zum Segmentende an. Response des Servers:
HTTP/2 206 Partial Content
Content-Length: 253265
Content-Range: bytes 245668-498933/498934
Das ist eine gewöhnliche 206-Response. Da die Inhaltslänge bekannt ist, enthält die Response den Content-Length Header. Alle Daten werden zu einem zusammenhängenden Block gebündelt, da das komplette Segment beim Origin vorliegt. Zur Fortsetzung der Wiedergabe muss der Client eine weitere Anfrage senden:
GET / v1_1-7729.m4s HTTP/2
Response des Servers:
HTTP/2 200
Der Server bündelt jeweils alle verfügbar werdenden Parts von Segment 7729 in einer Sammel-Response, so dass am Player eine Steady-State-Wiedergabe erfolgt.
Steady State
Was passiert bei einer kontinuierlichen Wiedergabe? Die nach dem Start des Players ausgetauschten Requests lassen sich wie folgt zusammenfassen:
GET / v1_1-7729.m4s HTTP/2
Range: bytes=567843-9007199254740991
GET / v1_1-7730.m4s HTTP/2
GET / v1_1-7731.m4s HTTP/2
GET / v1_1-7732.m4s HTTP/2
...
Die erste Anforderung setzt RFC8673 ein, weil das Start-Offset nicht bei null liegt. Ansonsten liegen hier ausschließlich normale GET-Requests ohne Range-Header vor. Erstaunlicherweise gilt hier ganz allgemein, dass ein LL-HLS-Client im Falle der Byte-Range-Adressierung für jeden Medientyp lediglich eine Anforderung pro Segmentdauer senden muss. LL-HLS gewinnt dadurch an Leistung, obwohl das Format verbose ist. Allerdings muss der Client die Playlist bei jedem Part-Intervall aktualisieren, damit er Informationen zum jeweiligen Zustand des Streams erhält. Die Verringerung der Gesamtanzahl an Requests hängt vom Verhältnis von Part- und Segmentdauer ab. Tabelle 1 fasst die Anzahl der Requests pro Segmentdauer in Zeitintervallen für einen LL-HLS-Client mit diskreter bzw. Range-basierter Adressierung der Parts zusammen.
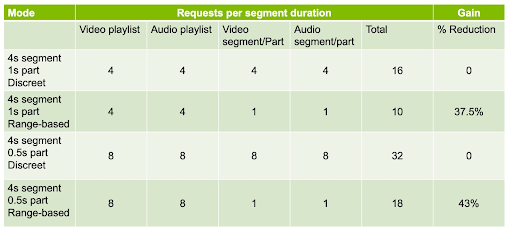
Tabelle 1
Sind die Segmente 4s und die Parts 1s lang, reduziert sich die Gesamtzahl der Anforderung alle 4 Sekunden um 37,5%. Sind die Parts nur 0,5s lang, erhöht sich diese Zahl sogar auf 43%. Dieser erhebliche Leistungszuwachs wirkt sich auf die Skalierbarkeit des CDN und die Gesamtkosten des Systems aus. Bei einer Million angeschlossenen Clients stellen 430.000 weniger Requests alle 4 Sekunden einen deutlichen Unterschied dar. Jeder an ein CDN gesendeter Request verursacht Kosten für Verbindungen, Rechenoperationen und Energie. Um die Effizienz der Verteilung zu maximieren, soll die Anzahl der Requests möglichst klein, die Qualität der Wiedergabe beim Endbenutzer dagegen möglichst hoch sein.
Segmentaufbau
Frühere Versionen der LL-HLS-Origins erzeugten ausschließlich unabhängige Parts (die also jeweils einen Keyframe enthielten) und anschließend zusammenhängende Segmente mit einem einzelnen Keyframe wie in Abbildung 10.
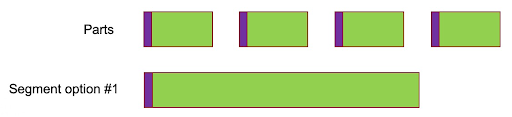
Abbildung 10
Das ist in der Effizienz der Kodierung begründet, die sich durch Verwendung der längeren GOP etwas steigern lässt. Der Preis dafür ist ein Verzicht auf die Portabilität eines einzelnen Objekts im Cache für die Bereitstellung von Parts und Segmenten. Um den Cache zu vereinheitlichen, muss das Segment aus verketteten Parts bestehen wie in Abbildung 11 dargestellt.

Abbildung 11
Die Vorteile einer Halbierung der Cachegröße überwiegen erheblich die geringe Effizienzsteigerung bei der Kodierung durch zwei Objekte mit unterschiedlichen Bits.
Abschätzung des Durchsatzes
Alle HTTP Adaptive-Streaming-Clients greifen zur Abschätzung des möglichen Durchsatzes auf den Download der Mediensegmente zurück, um ihren ABR-Algorithmus zu beschleunigen.
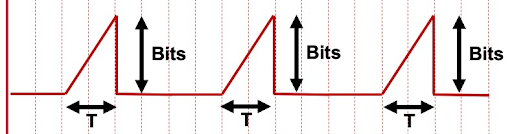
Abbildung 12
Bei der Lieferung diskreter Parts erfolgt dazu eine Messung der empfangenen Bits und die in Abbildung 12 dargestellte Division des Ergebnisses durch die Dauer des Empfangs. Da die Objekte vollständig auf dem Server liegen, hängt die Geschwindigkeit des Versands von der Übertragungsrate der Leitung ab, die daher zur Abschätzung des zusätzlich verfügbaren Durchsatzes verwendet werden kann. Eine Anwendung der gleichen Logik auf eine Sammel-Response mit Bereichsadressierung ergibt eine fehlerhafte Response. Während die Bits im Zähler korrekt sind, enthält der Nenner auch die Zeit des vom Origin gesperrten Versands (siehe Abbildung 13).
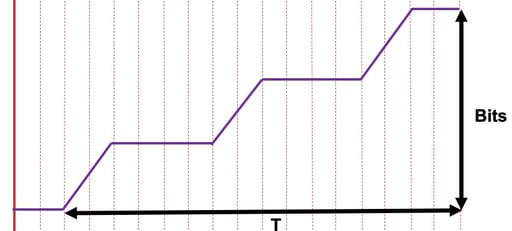
Abbildung 13
Der Player teilt die Gesamtanzahl der Bits im Mediensegment immer weiter durch die Übertragungsdauer, die im Wesentlichen der Wiedergabezeit des Segments entspricht. Das Ergebnis ist in diesem Falle immer gleich, nämlich dass der geschätzte Durchsatz gleich der codierten Bitrate des Objekts ist. Ein solches Ergebnis ist völlig sinnlos, da es nicht nur ungenau ist, sondern den Player auch davon abhält, auf eine höhere Bitrate umzuschalten.
Stattdessen sollte der Player den Durchsatz nur bei zunehmender Anzahl übertragener Bits abschätzen (siehe Abbildung 14).
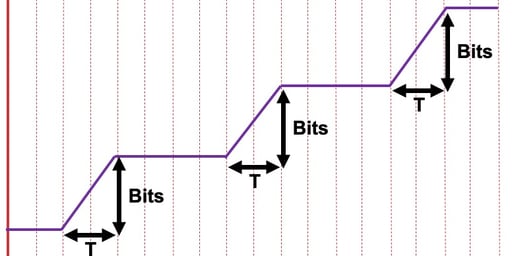
Abbildung 14
Wie kann der Player das erreichen? Praktischerweise beschreibt die Playlist die Part-Grenzen als Bereiche, während Origin und Edge-Server die Parts in jedem Fall bündeln. Überwacht der Player also seinen Empfangspuffer, kann er den Zeitpunkt des Empfangs der einzelnen Part-Grenze kennzeichnen und daraus den Durchsatz für den korrekten Teil des Akkumulationsfensters berechnen.
Soweit die Theorie, aber funktioniert das auch in der Realität?
Die in diesem Beitrag beschriebenen Konzepte wurden gemeinsam mit Ateme, einem französischen Anbieter von Encodern und Origin-Servern, im realen Internet überprüft. Ateme hat dazu im US-Bundesstaat Virginia einen Encoder sowie einen LL-HLS-Origin in einer AWS-Instanz installiert. Anschließend wurde darauf das Akamai CDN aufgesetzt und zum Streamen an einen im kalifornischen San Francisco befindlichen Client verwendet (siehe Abbildung 15).

Abbildung 15
Der Player war ein in Javascript erstelltes und deshalb im Browser ausführbares Testprogramm. Ein browserbasierter Player ist sehr praktisch zur Bewertung von Requests, Timing und CDN-Leistungen. Abbildung 16 zeigt einen Screenshot des laufenden Livestreams.
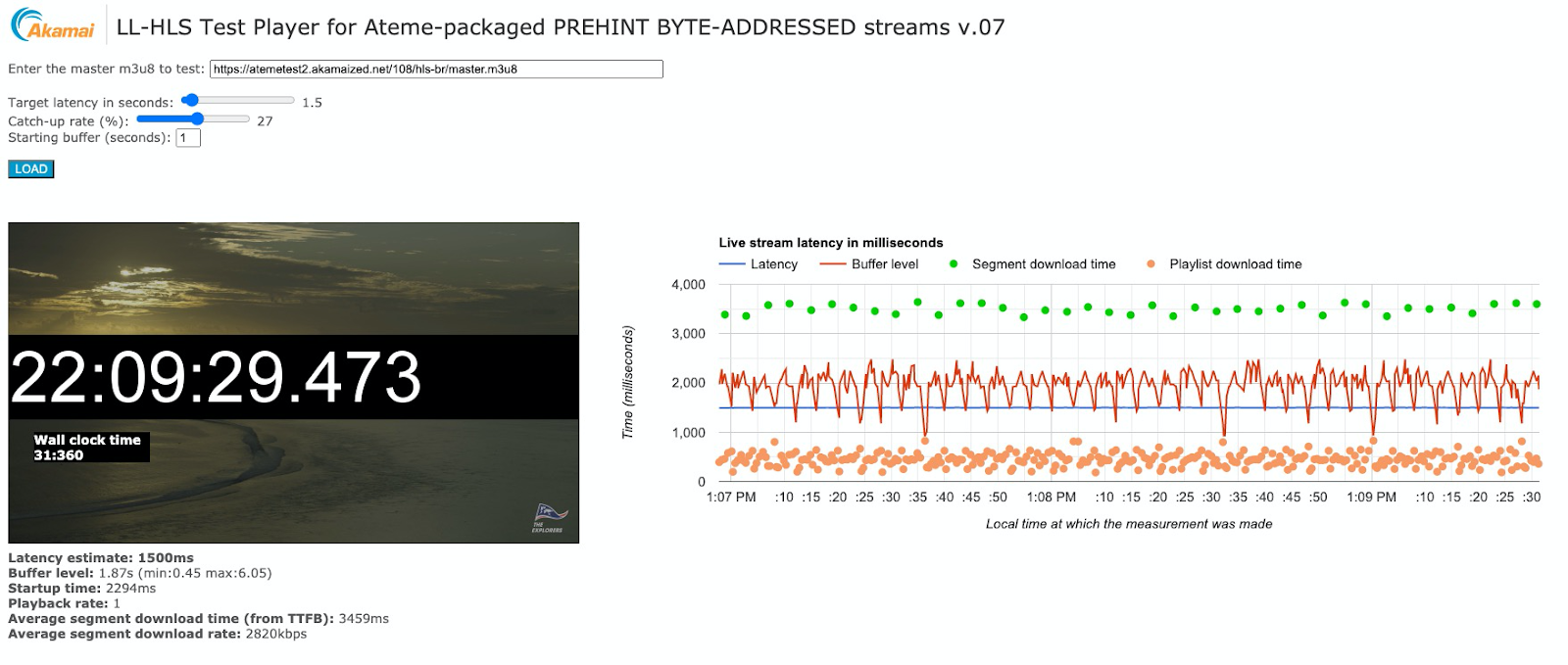
Abbildung 16
Der Livestream besteht aus 4s langen Segmenten mit 0,5s langen Parts. Er läuft mit einer Ende-zu-Ende-Latenz von 1,5ss. Die grünen Punkte im Diagramm rechts zeigen die Ausführung der Requests der einzelnen Mediensegmente. Diese dauern jeweils knapp unter 4s, was auch so zu erwarten war. Die orangefarbenen Punkte geben die Aktualisierungen der Playlist an, die alle 500 ms erfolgen. Die in Abbildung 17 dargestellten Requests der Videoobjekte machen deutlich,…
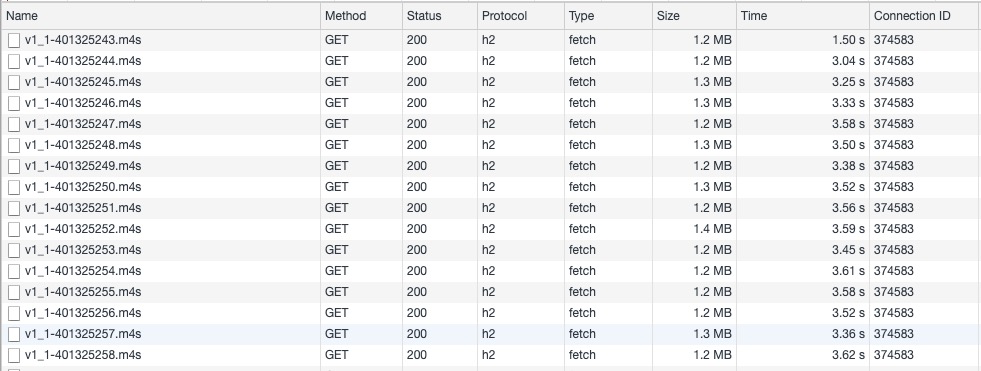
Abbildung 17
…dass immer nur Segmente angefordert werden und dass jeder Request eine 200-Response des Edge-Servers erhält, die nach knapp 4s bearbeitet ist. Interessant hierbei ist, dass mit LL-HLS eine Range-basierte Adressierung verwendet wird, der Client bei kontinuierlicher Wiedergabe jedoch keine bereichsbasierten Requests senden muss! Würde zunächst ein initialer Request mit einem Offset ungleich Null gestellt, hätte er die RFC8673-Konvention verwendet, angezeigt durch eine 206-Response auf einen vorausgegangenen CORS OPTIONS Request, um die Zulässigkeit des Range-Headers zu prüfen. Dieser Preflight-Request ist lediglich ein Artefakt des Testens von einem Browser aus und wäre beim Testen von einer nativen App aus nicht vorhanden. Die Aktualisierungen der Playlist (siehe Abbildung 18) erfolgen etwa alle 500ms und damit viel schneller als die der Mediensegmente. Jedes Mediensegment fordert mit der Query String _HLS_msn und -HLS_part eine aktualisierte Playlist an.
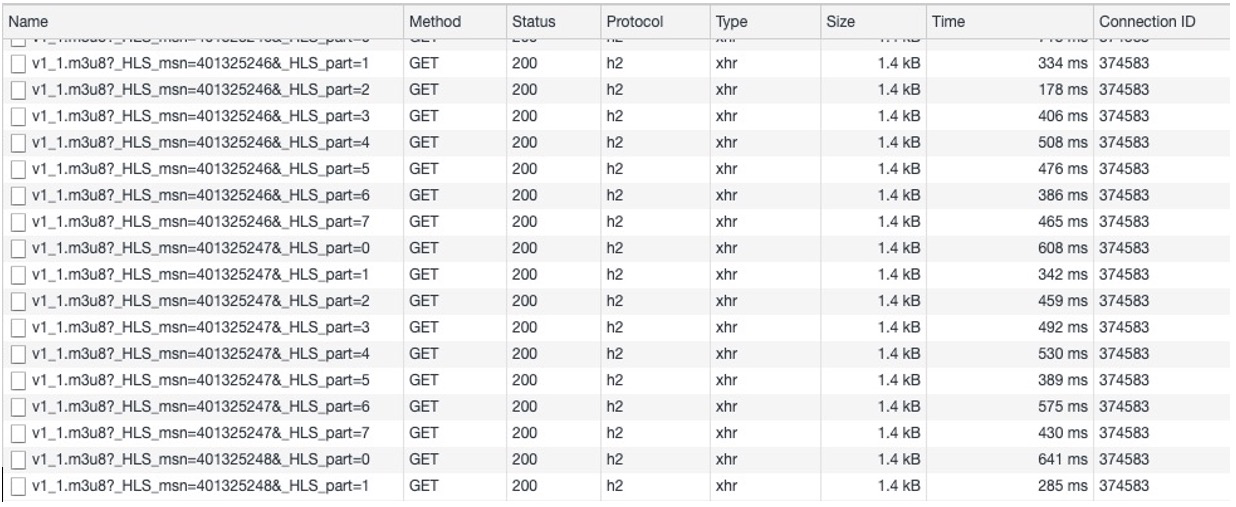
Abbildung 18
Abbildung 19 zeigt einen Ausschnitt aus den Mediensegment-Requests. Es gibt keinen Content-Range Response Header, da der Client immer vollständige Segmente anfordert. Und da hier eine aggregierte H2-Response gegen ein Objekt unbekannter Größe erfolgt, gibt es auch keinen Content-Length Response Header.
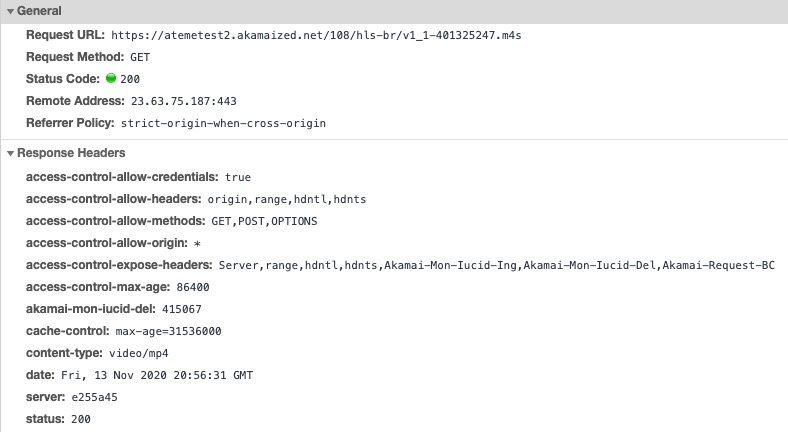
Abbildung 19
In Abbildung 20 sind die drei Zielplayer und die zeitparallele Darstellung der vom gleichen Origin und dem gleichen Edge-Server übertragenen Inhalte zu sehen. Unten links befindet sich der LL-HLS-Player mit Byte-Bereichsadressierung. Oben links läuft der LL-DASH-Player. Rechts ist ein HLS-Player mit normaler Latenz, dargestellt HLS.js.
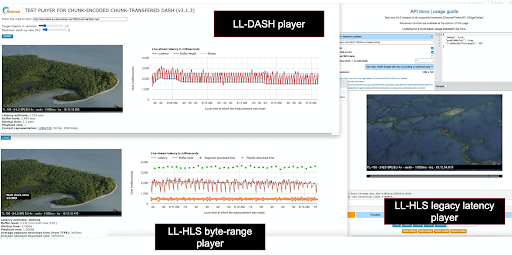
Abbildung 20
Zwar spielt der rechte Player genau den gleichen Stream ab wie der LL-HLS-Player, liegt aber 12s zurück, da er die einzelnen Parts ignoriert und stattdessen vor dem Start der Wiedergabe zunächst drei der 4s langen Segmente im Quellpuffer aufbaut. Abbildung 21 stellt die Bewertung des in diesem Beitrag verfolgten Ansatzes dar. Die Netzwerkverläufe der drei Player werden hier nebeneinander angezeigt. Jeder Player lädt das gleiche Mediensegment vom Edge-Server herunter (zum Beispiel 1-401326000.m4s,-).
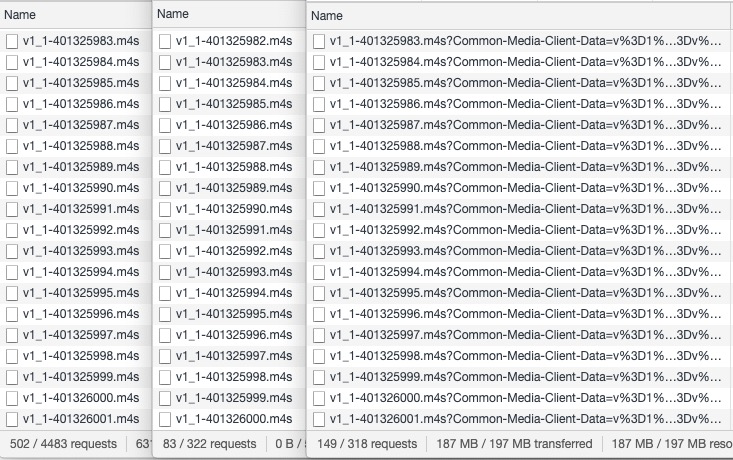
Abbildung 21
Der mittlere Bereich gehört zum Legacy-Latency-Player. Er liegt immer ein ganzes Segment hinter den anderen beiden Playern mit geringer Latenz, die das Objekt bereits während der Erstellung abrufen. Bei Betrachtung des ersten Players und seiner Anforderung eines bestimmten Segments vom CDN Edge wird deutlich, dass er eine TCP_MISS Response erhält (Abbildung 22). Der Inhalt lag im Edge also noch nicht vor, sodass dieser einen Forward Request beim Origin anfordern musste. Das entspricht dem normalen Verhalten, da zum Abrufen des Inhalts immer ein Request an den Origin gehen muss.

Abbildung 22
Wichtig ist, dass die zweite und alle nachfolgenden Requests nach demselben Objekt immer TCP_HIT als Response erhalten (Abbildung 23). Daraus geht hervor, dass sich das Objekt bereits im Cache des Edge befindet und von dort übertragen wird. Ein Erfolg!
Fazit
Mit dem Aufkommen der Range-basierten Adressierung für LL-HLS ergeben sich für Livestream-Anbieter eine Reihe von Vorteilen:
- Erhöhte Cache-Effizienz auf den Origin und CDN-Verteilungsebenen erhöht die Leistung und senkt die Betriebskosten
- Geringere Request-Rate von Clients. 30% bis 40% Verringerung für typische Encoding-Konfigurationen, was eine höhere CDN-gestützte Skalierung ermöglicht, die Betriebskosten senkt und die Häufigkeit von Request-Fehlern reduziert
- Ein LL-HLS-Client unter Steady-State-Wiedergabe muss keine Range-Requests an den Origin stellen, selbst wenn in der Playlist eine Range-basierte Adressierung verwendet wird. Dadurch entfallen die CORS-Preflight-Anforderungen für browserbasierte Clients, was die Latenz verbessert, mit der Playlists und Segmente wiedergegeben werden können
- Kompatibilität von vier unterschiedlichen Clients: HLS-Clients mit niedriger Latenz, HLS-Clients mit Standardlatenz (entspricht auch LL-HLS-Clients, die von live zurückscrubben), DASH-Clients mit niedriger Latenz sowie DASH-Clients mit Standardlatenz
- Wenn ein CDN in der Distributionskette vorhanden ist, muss RFC8673 auf der Origin-, CDN- und Client-Ebene unterstützt werden, um effektiv zu laufen. Besteht eine Direktverbindung zwischen den Clients und dem Origin, kann man davon ausgehen, dass sich der Origin entsprechend verhält und kein RFC8673 erforderlich ist.
Seit Oktober 2020 unterstützt Adaptive Media Delivery (AMD) von Akamai auch RFC8673 produktiv. Es muss über die Metadaten aktiviert werden, also kontaktieren Sie bitte Ihren Kundenbetreuer, wenn Sie an einem Test interessiert sind.
Wir sehen dem großflächigen Einsatz von interoperablem Low-Latency-Streaming mit großer Erwartung entgegen. Gerne beantworte ich Ihre Fragen zu diesem Thema.